Not professorware - g:Profiler turns 18 and helps thousands of researchers yearly!
g:Profiler, a popular gene list analysis tool, celebrates 18 years since its first publication in Nucleic Acids Research. What began as a student project has become a globally cited resource, with its 2019 update article now surpassing 5,000 citations — a testament to its lasting impact in life sciences.
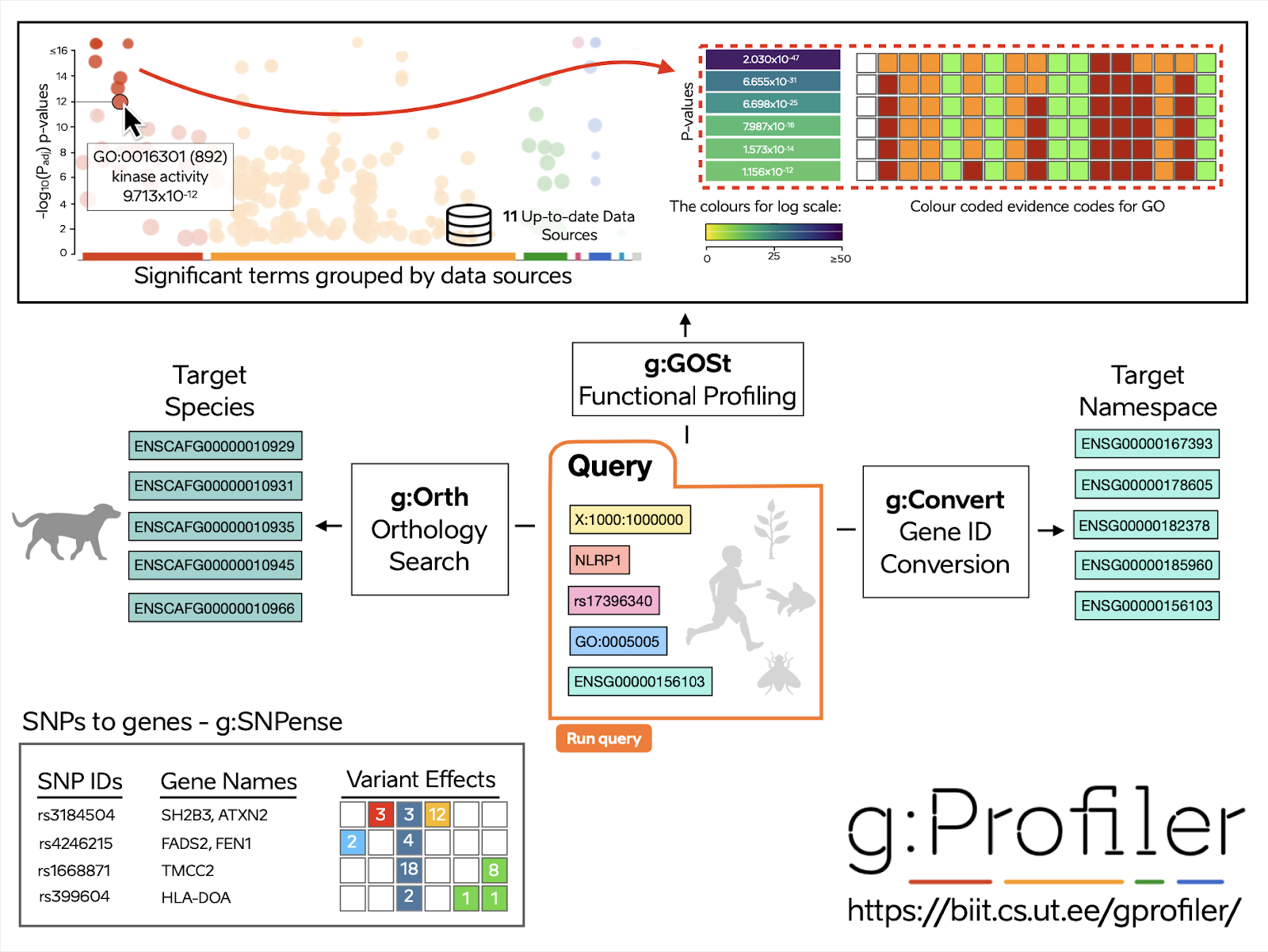
g:Profiler is a public web server that helps to analyse and interpret gene lists. Its core tool, g:GOSt (Gene Ontology Statistics), performs statistical enrichment analysis to help users put their gene sets into the context of previously known biological functions and processes. Other tools include g:Convert for gene ID conversion, g:Orth for mapping homologous genes across species, and g:SNPense for linking human SNPs to gene information and predicted variant effects.
g:Profiler is developed and maintained in Estonia at the University of Tartu, Institute of Computer Science. Launched initially as a student project based on a tool named EP:GO, GOSt has since evolved into the most widely used tool in the g:Profiler suite. The entire toolset is freely available as a web application and via multiple programmatic access points. Its development has been made possible thanks to the support of the Estonian Research Council and the European Union European Regional Development Fund.
This summer g:Profiler will celebrate 18 years since its first publication in Nucleic Acid Research. It is one of the few tools from the original set of 130, published in the journal at the same time, that is still functional and accessible via its original web address. Head of ELIXIR Estonia, Hedi Peterson, who oversees g:Profiler development nowadays, said, “The journey of maintaining and improving a tool in almost two decades is a testament to the dedication and hard work of the team.” Over the years, g:Profiler has undergone significant changes. In 2017-2019, a major technological upgrade was made, where both the back-end and front-end were entirely rewritten. Jüri Reimand initially developed the tool as his undergraduate and PhD work. Later maintained and improved by Tambet Arak, it has been kept at the technological forefront by scientific programmer Uku Raudvere in recent years. Maintaining and developing g:Profiler further has been a team effort. Critical novel developments were proposed and implemented by Dr. Liis Kolberg and executed at the front-end by Ivan Kuzmin. Dr. Priit Adler and the original EP:GO author and supervisor of Jüri Reimand, professor Jaak Vilo, contributed ideas during the brainstorm-heavy year of 2018.
g:Profiler is not just a valuable tool for web users; it also serves as a crucial building block for many other tools within bioinformatics workflows. We know at least 27 tools that utilise g:Profiler’s service as part of their pipeline. While this includes seven tools developed by ELIXIR Estonia, with ClustVis being the most well-known among them, the majority of the tools are developed by international researchers. These tools make use of our R and Python packages, Galaxy client and the API to use our core g:Profiler services — most commonly g:Convert for the conversion of identifiers and g:GOSt for gene set enrichment analysis — highlighting the vital role of g:Profiler in various bioinformatics applications. The capacity to integrate data and convert hundreds of identifier types seamlessly for close to 800 organisms was recognised in the first round of ELIXIR Recommended Interoperable Resource selection in 2018, where g:Profiler was named.
Among the external tools and applications that have integrated g:Profiler services into their analysis workflows, the Enrichment Table App for Cytoscape might be the most widely known. It allows users to perform enrichment analysis directly within Cytoscape networks using g:Profiler’s web service. Other tools, such as the R package bulkAnalyseR (article), also utilise g:Profiler for enrichment analysis of differentially expressed genes.
The 24th of March this year marked a significant milestone that not all research articles or software ever make - the 2019 article reached 5000 citations! For several reasons, the 2019 g:Profiler article has gathered significantly more citations than other g:Profiler papers. While the original 2007 article introduced the tool and established its initial utility, subsequent updates in 2011 and 2016 added smaller improvements. However, the 2019 paper stands out due to its all-around update that significantly enhanced the tool’s functionality and user experience. This update incorporated major new features and improvements, such as the customizability of the results tables and the Manhattan plot for an easy overview of the results, making g:Profiler more versatile and easier to use. It also improved integrability with other bioinformatics tools and databases, broadening its applicability and appeal. Published in the widely known Web Server Issue in Nucleic Acids Research, the 2019 article provides detailed documentation and practical examples, which further increased its adoption and citation.
The high number of citations for the tool boosts the motivation to elevate the tool, especially for the developers. As Uku noted, “The avalanche of citations the tool has gathered in 18 years validates that what we do is important and affects various scientific disciplines. This encourages us to improve our services (whether old or new) even more.” In addition to citations, the number of active users who contact us with questions or suggestions is also highly motivating. Their engagement confirms that the tool is being actively used and appreciated, and it provides valuable insights that help guide further improvements. This achievement illustrates the importance of developing and maintaining free-to-use, high-quality tools that can drive scientific progress. Properly developed and well-maintained tools are essential for ensuring that research remains accurate, efficient, and innovative over time.
Link to the 2019 g:Profiler article: https://doi.org/10.1093/nar/gkz369